ウェブ開発

聯經數位(Linking Digital)
AIキャラクター識別およびスマートオーディオブック自動生成システムの開発
AI音声と自然言語処理(NLP)技術の進化を受け、聯經數位は「スマートオーディオブック自動生成プラットフォーム」の開発に着手しました。 本プロジェクトは、生成AIを通じて電子書籍を感情豊かなキャラクターボイスへと変換します。 テキストの構造化分解と自動配役により、従来のナレーション制作におけるコストと時間の壁を打破し、出版業界をAIスマート制作の時代へと導きます。

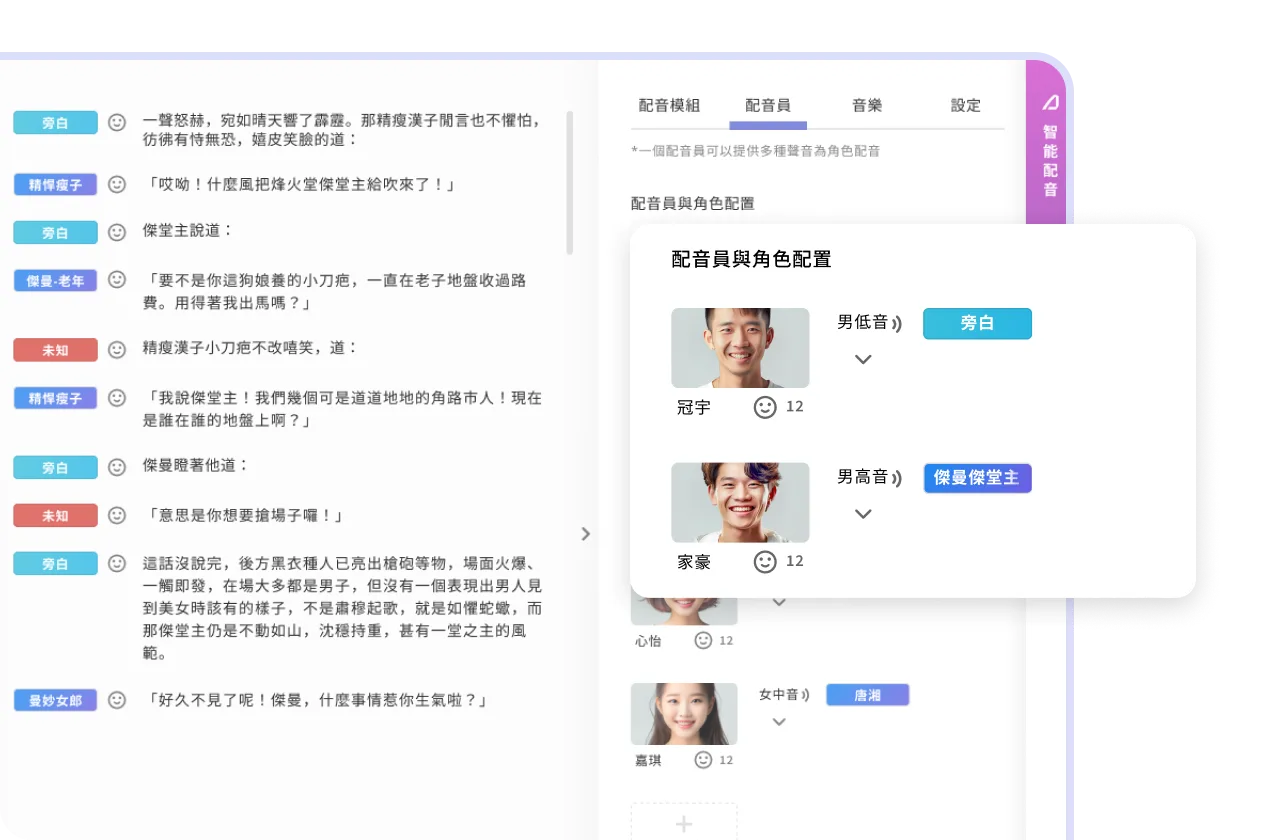
読書体験の没入感を高めるため、聯經數位は静的なコンテンツを感情豊かな音声へとアップグレードすることに注力しています。 • 開発動機: AI音声技術により、テキストをキャラクター性の際立つ自然なナレーションへ変換します。 • 業界トレンド: 生成AIの普及により、デジタルコンテンツ市場の高速なサイクルに対応する自動配音フローの導入が不可欠となっています。 • 知能化のビジョン: テキスト解析、キャラクター識別、自動配音を統合したスマートワークフローを構築し、出版のDXを実現します。
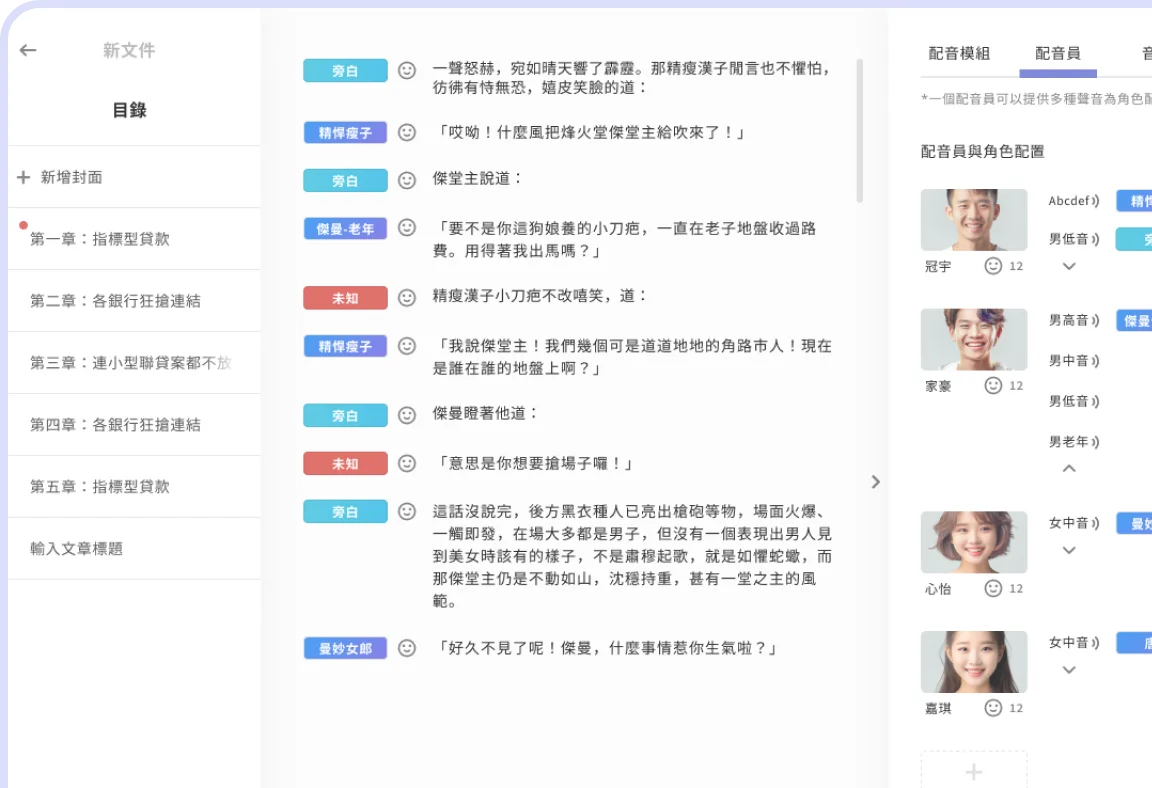
膨大な電子書籍の内容を、章・段落・文章ごとに正確かつ自動的に分解する技術が求められました。
中英両言語において、地の文と会話文を正確に識別し、対応する感情や声の質を判定する必要があります。
小説1冊を「2分以内」で解析・分析完了させる必要があり、計算効率とAPI連携の最適化が不可欠でした。
多言語対応、配音モジュールの共通化、地域を越えた権限管理など、グローバル展開を視野に入れた設計が必要です。
キャラクター単位で音声設計と感情表現を行うことで、リスナーの没入感とコンテンツの質を根本から向上させました。
ファイルアップロードから、解析、識別、感情分析、音声合成に至る一貫した生産チェーンを設計しました。
並列コンピューティング・アーキテクチャにより複数のChatGPT APIを連携。キャラクター識別率90%以上、テキスト分解率75%以上の基準を設定し、品質を担保しました。
キャラクターや配音の設定を再利用可能にすることで、シリーズ作品などの続刊制作期間を大幅に短縮しました。
コア開発フレームワーク
ASP.NET Core (C#) をメインに採用し、システムの堅牢性と高並列処理能力を確保しました。
AI意味解析エンジン
Azure OpenAI (ChatGPT API) と連携し、配役判定、感情検知(年齢、性別、特徴を含む)、文脈解析を実行します。
構造化処理 API
中英バイリンガル対応の書籍分解を自動化し、AIによる一文ごとのタグ付けを容易にする構造化データを生成します。
数週間を要していた作業を分単位に短縮し、コンテンツの供給能力を最大化しました。
AIによる安定した論理判定により、人の疲労や主観に左右されない一貫した感情表現を保証します。
DXの成功により、国際競争力を持つAIデジタル資産プラットフォームを確立し、市場をリードするエコシステムを構築しました。