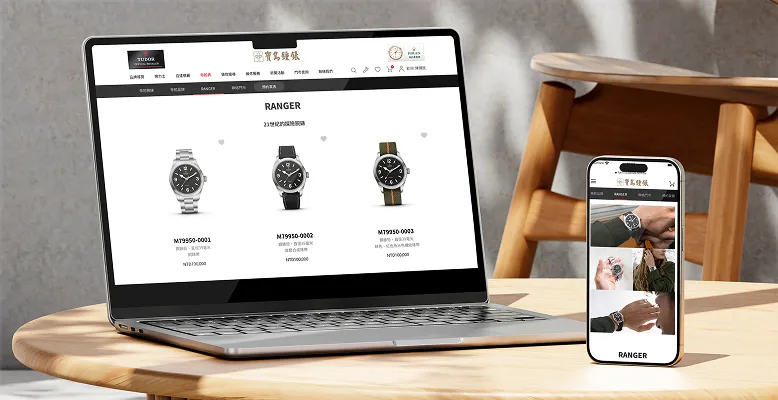
網頁開發

強基金|基金投資社群平台
強基金作為台灣最大共同基金投資社群,致力於提供中立、透明的資訊與討論空間。本專案啟動網站體驗全面升級計畫,透過獨家 FBI 指標(AI 燈號)與資訊分層設計,解決高密度數據帶來的閱讀負擔。
查看更多聯經數位
電子有聲書 智慧生成與 AI 角色 辨識系統開發
隨著 AI 語音與自然語言處理(NLP)技術成熟,聯經數位啟動「電子有聲書智慧生成平台」開發計畫。 本專案透過生成式 AI 技術,將靜態電子書轉化為具備情感與鮮明角色的有聲內容。 系統實現了文字結構化拆解、自動角色辨識與情緒標記,大幅突破傳統配音人工成本高、效率低的瓶頸,引領出版業跨入 AI 智慧製作時代。

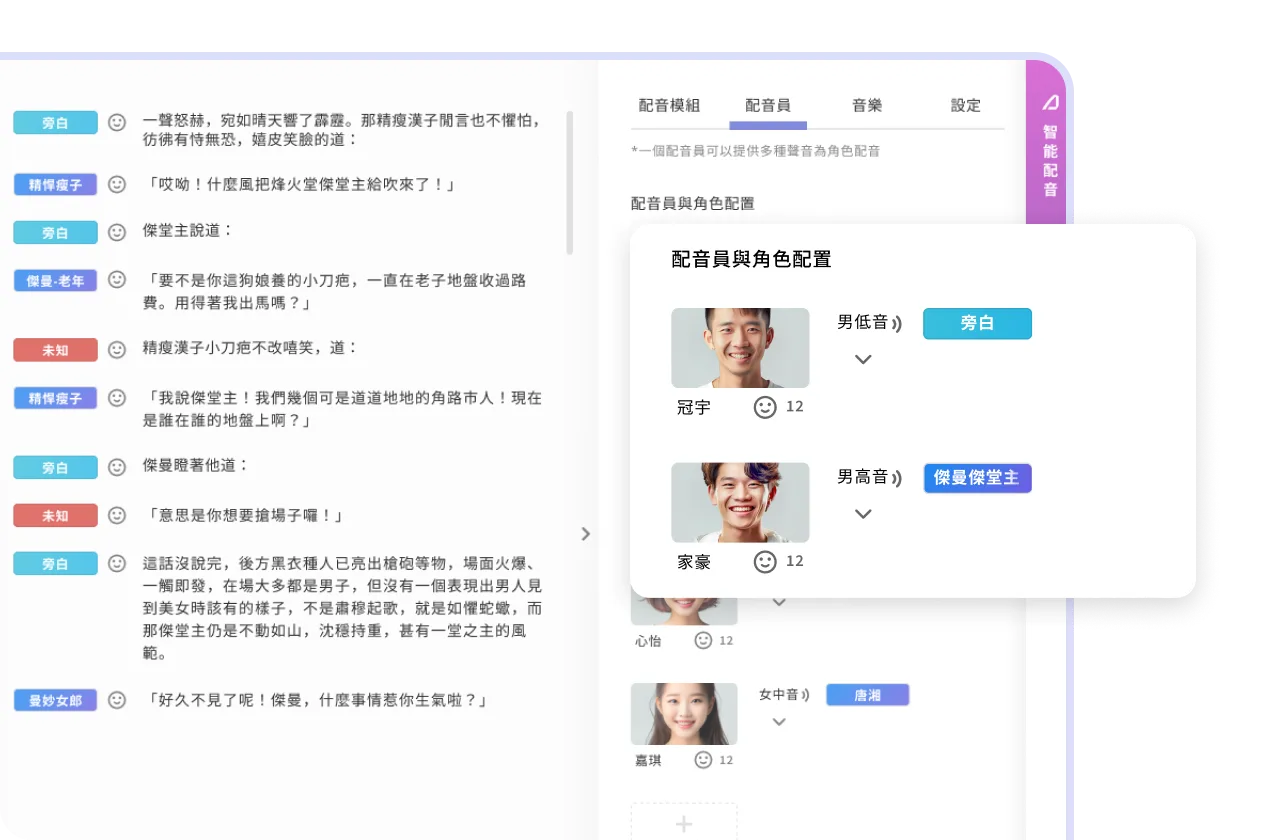
聯經數位為提升閱讀體驗的沉浸感,致力於將靜態電子書升級為情感豐富的有聲內容。 • 開發動機: 利用 AI 語音技術,將文字內容轉化為角色鮮明、語氣自然的智慧有聲書。 • 產業趨勢: 隨著生成式 AI 發展,傳統出版需結合自動化配音流程,以應對數位內容市場的快速更迭。 • 智慧化願景: 打造一套結合文字拆解、角色辨識與自動配音的智慧流程,實現出版流程的數位轉型。
如何將海量電子書內容自動依據章節、段落、句子完成精準拆解。
需從中/英文內容中,準確識別敘述者與角色對話,並判別對應的情緒與聲音特質
系統需在「兩分鐘內」完成整本小說的辨識與分析,對運算效率與 API 串接極具考驗。
系統需具備多語系支援、角色配音模組化及跨地區權限管理能力,支援全球化佈局。
以角色為單位進行聲音設計與情感呈現,從根本提升聽眾的沉浸感與內容質感。
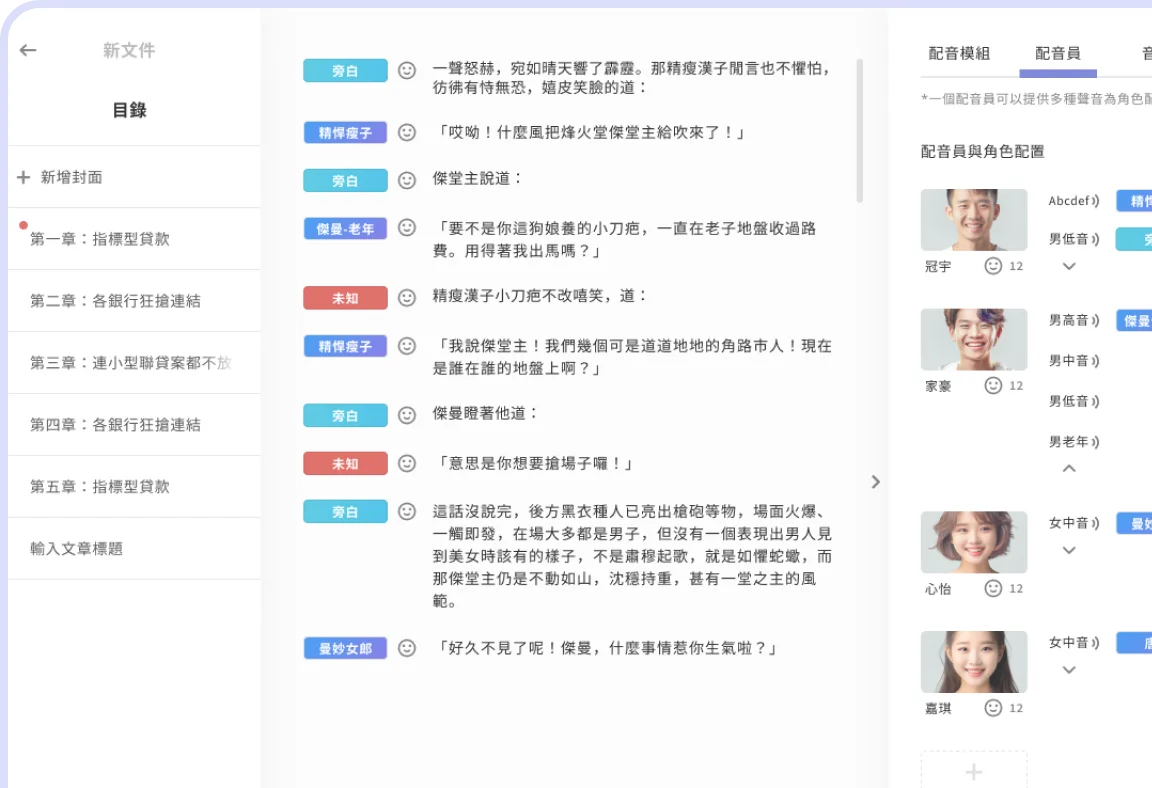
設計從原始檔上傳、文本拆解、角色辨識、情緒分析、聲音標記到語音合成的完整生產鏈。
建置平行運算架構串接多組 ChatGPT API,確保大型文本的高效分析處理。系統設定角色辨識達 90%、文本拆解達 75% 以上的成功率門檻,保障輸出品質穩定可靠。
角色與配音模組可重用,大幅縮短後續同系列書籍的製作週期。
核心開發框架
以 ASP.NET Core (C#) 為主架構,確保系統的穩健性與高併發處理能力
AI 語意分析引擎
串接 Azure OpenAI (ChatGPT API),執行角色判讀、情緒偵測(含年齡、性別、聲音特質)與語意分析。
結構化處理 API
自動執行中英雙語的書籍拆解,將內容轉化為結構化資料,便於 AI 逐句標註。
將原本需數週人工判讀的工作縮短至分鐘級別,極大化內容產能。
透過 AI 穩定的辨識邏輯,確保有聲書中角色情緒的一致性,不再受人為疲勞或主觀因素影響。
成功的技術轉型為聯經建立起具備國際競爭力的 AI 數位資產平台,領先市場佈建有聲閱讀生態系。